Within AI Tutors
When Should You Search Instead?
Some questions are safer to start with search results because the source trail matters more than a smooth explanation.
On this page
- Facts that need direct sourcing
- Claims where freshness changes the answer
- How to switch from chatbot summary to source trail
Page outline Jump by section
Introduction
Chatbots are often the fastest way to get an explanation, but some questions are safer to begin with a search rather than an answer. The key distinction is not whether the chatbot is intelligent; it is whether the value of the information depends on a visible source trail. When accuracy, accountability, legal responsibility, or recent developments matter, readers need to see where a claim came from before they decide whether to trust it.
 This is especially important in the age of social media and AI, where polished wording can make uncertain information appear settled. Research on generative search systems has repeatedly found cases where answers contain unsupported claims, inaccurate citations, or source mismatches even when links are provided. In those situations, starting with sources rather than summaries is often the more reliable critical-thinking strategy. [Columbia Journalism Review+2arXiv]cjr.orgwe compared eight ai search engines theyre all bad at citing newsColumbia Journalism ReviewAI Search Has a Citation ProblemMar 6, 2025 — The Tow Center for Digital Journalism conducted tests on eight ge…
This is especially important in the age of social media and AI, where polished wording can make uncertain information appear settled. Research on generative search systems has repeatedly found cases where answers contain unsupported claims, inaccurate citations, or source mismatches even when links are provided. In those situations, starting with sources rather than summaries is often the more reliable critical-thinking strategy. [Columbia Journalism Review+2arXiv]cjr.orgwe compared eight ai search engines theyre all bad at citing newsColumbia Journalism ReviewAI Search Has a Citation ProblemMar 6, 2025 — The Tow Center for Digital Journalism conducted tests on eight ge…
Facts That Need Direct Sourcing
Some questions are fundamentally source-dependent. The issue is not that a chatbot cannot answer them; it is that the answer is difficult to evaluate without seeing the evidence.
A source-first approach is usually preferable when dealing with:
- Statistics, survey results, and numerical claims.
- Scientific findings and medical evidence.
- Legal rules, regulations, and court decisions.
- Academic quotations and references.
- Government policies and official guidance.
- Historical claims that depend on primary documents.
- Statements about what a person or organisation supposedly said.
Consider a simple question such as, “What percentage of adults use social media daily?” A chatbot may provide a number and sound confident. Yet the answer depends on which survey was conducted, when it was conducted, how the question was asked, and which population was measured. Without the original source, the reader cannot judge whether the figure is current, representative, or even accurately quoted.
The same logic applies to academic citations. Large language models are known to generate convincing but inaccurate references, including incorrect article titles, author names, publication details, and digital object identifiers (DOIs). Researchers and educators have repeatedly documented these failures, making direct verification essential whenever references matter. [NIST]nist.govhallucination detection large language models using diversion decodingHallucination Detection in Large Language Models Using…by B Abdeen · 2025 · Cited by 1 — Despite their advanced text generation ca…
In these cases, the safest workflow is to locate the source first, then use the chatbot to help interpret it.
Claims Where Freshness Changes the Answer
Some information is not fixed. It changes daily, weekly, or even hourly.
Examples include:
- Breaking news.
- Election results.
- Company announcements.
- Product recalls.
- Public-health guidance.
- Court rulings.
- Financial data and market information.
A chatbot’s training may not include the latest developments, and even systems with web access can misinterpret recent information. Source-first searching allows readers to inspect the original publication date, identify updates, and compare multiple reports.
Recent legal disputes surrounding AI-generated search summaries illustrate why freshness and sourcing matter. In 2026, a German court ruled that Google could be held liable for false statements generated by its AI Overview feature, emphasising that users often perceive these summaries as direct assertions rather than merely links to third-party content. The case arose from incorrect claims generated in search summaries and highlighted the practical consequences of relying on AI-generated explanations without checking underlying sources. [Reuters+2WIRED]reuters.comThe Munich court characterized the content produced by AI Overviews as Google's own, making the company responsible for any false claims…
Health information provides another strong example. Investigations into AI-generated search summaries have found instances where health-related answers lacked important context or contained misleading interpretations. Even when the cited sources were reputable, the summarised conclusion was not always fully supported by the underlying material. [Tom's Guide]tomsguide.comThe investigation cited instances like incorrect information on liver blood tests, misleading dietary advice for pancreatic cancer patien…
The lesson is simple: if the answer could change tomorrow, search first.
Why a Fluent Answer Is Not Evidence
One of the most important critical-thinking habits in the AI era is separating explanation quality from evidence quality.
Chatbots are designed to produce coherent language. Their responses often feel complete because they are written in a confident, conversational style. However, fluency and accuracy are different things.
Researchers studying generative search engines have found recurring problems with verifiability. A widely discussed study of AI-powered search systems reported that more than 60% of tested citation behaviours contained significant problems when identifying and referencing news content. Other research has found that many generated claims are not fully supported by the sources attached to them. [Nieman Lab+2Columbia Journalism Review]niemanlab.orgNieman LabAI search engines fail to produce accurate citations in over…AI search engines fail to produce accurate citations in over 60…
More recent work examining Google AI Overviews analysed tens of thousands of individual claims and found that roughly 11% were unsupported by the cited pages. Importantly, the cited source itself could be credible while still failing to support the specific statement made by the AI system. [arXiv]arxiv.orgMeasuring Google AI Overviews: Activation, Source Quality…13 May 2026 — Third, decomposing responses into 98,020 atomic claims, 1…
This creates a subtle risk. Readers may see a citation and assume the claim has been verified. In reality, the source may not say what the answer implies.
For critical thinkers, the question should not be “Was a source provided?” but “Does the source actually support the claim?”

How to Switch From Chatbot Summary to Source Trail
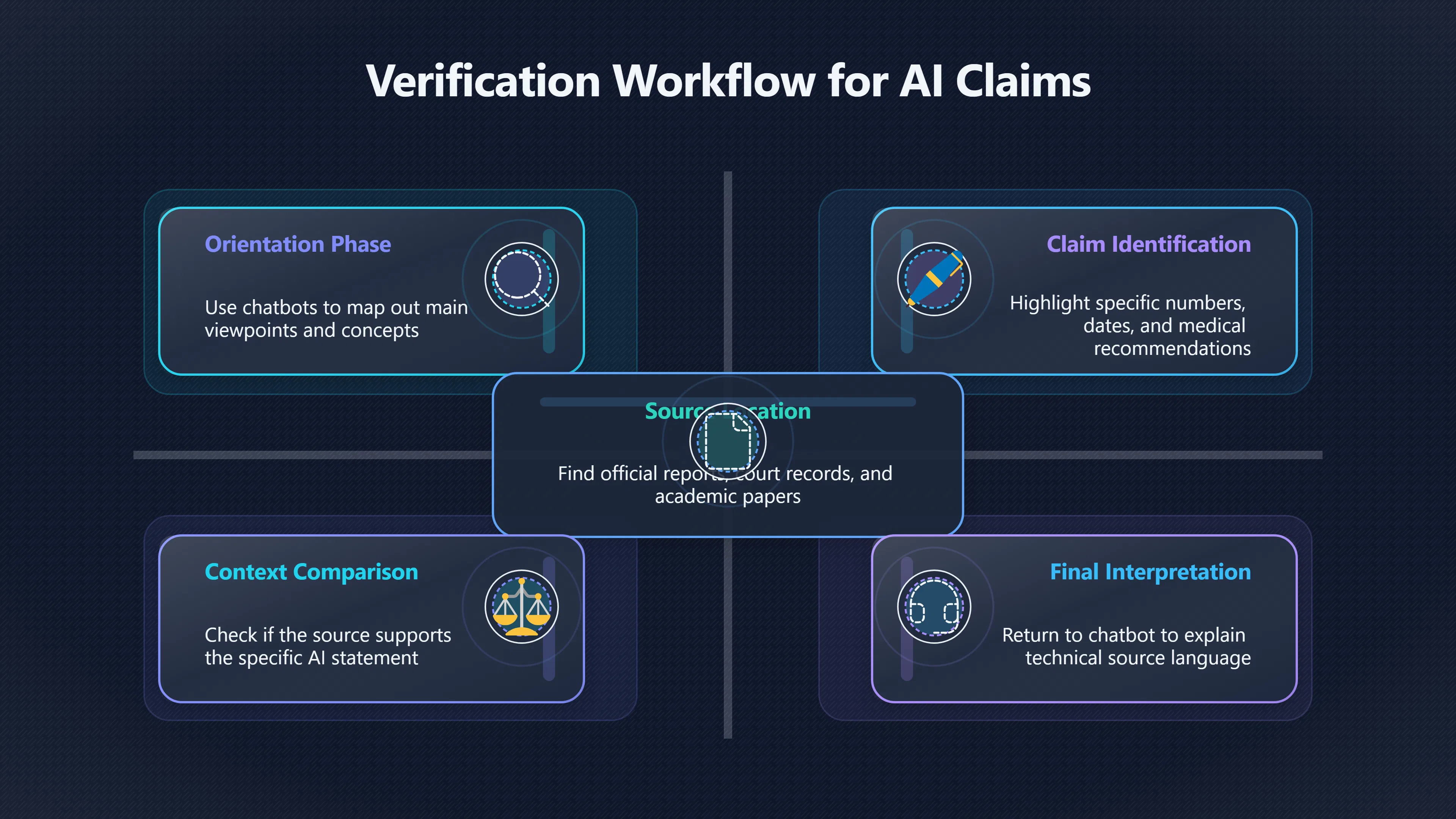
A practical approach is to use chatbots and search engines together rather than treating them as competitors.
Step 1: Use the chatbot for orientation
Ask broad questions such as:
- What are the main viewpoints?
- What concepts should I understand first?
- Which organisations are involved?
- What terms should I search for?
This stage is about building a map of the topic.
Step 2: Identify the key factual claims
Highlight any statement that would matter if it were wrong.
Examples include:
- Numbers and percentages.
- Dates and timelines.
- Medical recommendations.
- Legal requirements.
- Direct quotations.
- Statements about current events.
Step 3: Locate original sources
Search for:
- Official reports.
- Government documents.
- Academic papers.
- Court records.
- Company filings.
- Primary interviews.
Whenever possible, read the original material rather than relying solely on summaries of it.

Step 4: Compare the source with the summary
Ask:
- Does the source actually say this?
- Was important context omitted?
- Is uncertainty being presented as certainty?
- Is the information current?
This step often reveals where simplification has introduced distortion.
Step 5: Return to the chatbot for explanation
Once the source is identified, the chatbot becomes more useful. It can help explain technical language, summarise long documents, compare findings, or generate questions for deeper reading.
The chatbot becomes a guide to understanding evidence rather than a substitute for it.
A Simple Rule for Critical Thinkers
When the goal is understanding a concept, a chatbot can often be the best starting point. When the goal is establishing whether a factual claim is true, current, or accurately represented, start with the source.
In practice, that means searching first whenever the answer depends on evidence rather than explanation. The more important the consequences of being wrong, the more valuable the source trail becomes. Critical thinking in the age of AI is not only about questioning answers; it is about knowing when an answer should come after the evidence instead of before it.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.




Endnotes
-
Source: arxiv.org
Title: arXiv Evaluating Verifiability in Generative Search Engines
Link: https://arxiv.org/abs/2304.09848 -
Source: arxiv.org
Link: https://arxiv.org/html/2605.14021v1Source snippet
Measuring Google AI Overviews: Activation, Source Quality...13 May 2026 — Third, decomposing responses into 98,020 atomic claims, 1...
Published: May 2026
-
Source: nist.gov
Title: hallucination detection large language models using diversion decoding
Link: https://www.nist.gov/publications/hallucination-detection-large-language-models-using-diversion-decodingSource snippet
Hallucination Detection in Large Language Models Using...by B Abdeen · 2025 · Cited by 1 — Despite their advanced text generation ca...
-
Source: reuters.com
Link: https://www.reuters.com/world/google-appeal-german-court-ruling-assigning-liability-ai-overviews-false-claims-2026-06-12/Source snippet
The Munich court characterized the content produced by AI Overviews as Google's own, making the company responsible for any false claims...
-
Source: wired.com
Link: https://www.wired.com/story/a-court-has-ruled-that-google-is-liable-for-false-statements-generated-by-ai-overviewsSource snippet
The Munich Regional Court found that the feature generated misleading summaries incorrectly linking two publishers to scams and fraudulen...
-
Source: nvlpubs.nist.gov
Title: Trustworthy AI
Link: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdfSource snippet
Intelligence Risk Management Frameworkby N AI · 2024 · Cited by 125 — Additionally, generative AI models can assist malicious actors in c...
-
Source: nist.gov
Link: https://www.nist.gov/ai-test-evaluation-validation-and-verification-tevvSource snippet
AI test, evaluation, validation and verification (TEVV) | NISTNIST conducts research and development of metrics, measurements, and evalua...
-
Source: nist.gov
Link: https://www.nist.gov/trustworthy-and-responsible-aiSource snippet
ity and Resiliency; Accountability and Transparency...
-
Source: ai-challenges.nist.gov
Link: https://ai-challenges.nist.gov/genaiSource snippet
Evaluating Generative AI - NIST AI ChallengesNIST GenAI is an umbrella program that supports various evaluations for research and measure...
-
Source: journalism.columbia.edu
Title: tow ai report 2025
Link: https://journalism.columbia.edu/news/tow-ai-report-2025Source snippet
Center's Latest Report on AI Search Engines5 Mar 2025 — The Tow Center for Digital Journalism conducted tests on eight generative search...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2605.14021Source snippet
Measuring Google AI Overviews: Activation, Source Quality...by H Xu · 2026 — Third, decomposing responses into 98,020 atomic claims, 11...
-
Source: cloud.google.com
Title: what are [ai hallucinations]({{ ‘hallucinations/’ | relative_url }})
Link: https://cloud.google.com/discover/what-are-ai-hallucinationsSource snippet
are AI hallucinations?AI hallucinations are incorrect or misleading results that AI models generate. These errors can be caused by a vari...
-
Source: cjr.org
Title: we compared eight ai search engines theyre all bad at citing news
Link: https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.phpSource snippet
Columbia Journalism ReviewAI Search Has a Citation ProblemMar 6, 2025 — The Tow Center for Digital Journalism conducted tests on eight ge...
-
Source: tomsguide.com
Link: https://www.tomsguide.com/ai/google-pulls-ai-overviews-on-some-health-queries-after-claims-they-mislead-usersSource snippet
The investigation cited instances like incorrect information on liver blood tests, misleading dietary advice for pancreatic cancer patien...
-
Source: niemanlab.org
Title:
Link: www.cjr.org ➚ | Posted by: Andrew Deck
Link: https://www.niemanlab.org/2025/03/ai-search-engines-fail-to-produce-accurate-citations-in-over-60-of-tests-according-to-new-tow-center-study/Source snippet
Nieman LabAI search engines fail to produce accurate citations in over...AI search engines fail to produce accurate citations in over 60...
-
Source: ai.google
Title: Google AI
Link: https://ai.google/Source snippet
How we're making AI helpful for everyoneDiscover how Google AI is committed to enriching knowledge, solving complex challenges and helpin...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/niemanlab-harvard-university_httpswwwniemanlaborg202503ai-search-engines-fail-to-produce-accurate-citations-in-over-activity-7304945141746749440-C8LQSource snippet
Nieman Journalism Lab's Post10 Mar 2025 — AI search engines fail to produce accurate citations in over 60% of tests, according to new Tow...
Additional References
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/ai-hallucinations-new-supply-chain-risk-how-organizations-can-yeuzcSource snippet
AI Hallucinations Are the New Supply-Chain RiskWhat exactly is an AI hallucination? · Factually wrong, · Fabricated, or · Not grounded in...
-
Source: pcgamer.com
Link: https://www.pcgamer.com/software/ai/google-claims-most-users-know-information-generated-with-ai-should-not-be-blindly-trusted-but-a-court-ruled-its-still-liable-for-false-claims-made-in-ai-overview/Source snippet
The case centered on misinformation that misattributed unethical practices to two Munich-based publishers—claims derived not from origina...
-
Source: docs.modulos.ai
Link: https://docs.modulos.ai/frameworks/nist-ai-rmf/trustworthy-aiSource snippet
AI RMF Trustworthy AI Characteristics (NIST AI 100-1)The 7 characteristics are: valid and reliable, safe, secure and resilient, accountab...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/404890793_Measuring_Google_AI_Overviews_Activation_Source_Quality_Claim_Fidelity_and_Publisher_ImpactSource snippet
Measuring Google AI Overviews: Activation, Source Quality...17 May 2026 — Third, decomposing responses into 98,020 atomic claims, 11.0%...
Published: May 2026
-
Source: ziptie.dev
Link: https://ziptie.dev/blog/how-different-ai-platforms-cite-the-same-source-differently/Source snippet
Low accuracy across all platforms. The CJR Tow Center study found 60%+ error rates across 1,600 tests. GPT-4o...Read more...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/ai-ducator_why-nist-uses-confabulation-instead-of-activity-7418556300634136576-IoV9Source snippet
NIST prefers confabulation over hallucination in AI gap-fillingJan 17, 2026 — Why NIST Uses "Confabulation" instead of "Hallucination"...
-
Source: medium.com
Title: the 55 393 query audit exposes googles citation revenue trap f452e242dca4
Link: https://medium.com/kairi-ai/the-55-393-query-audit-exposes-googles-citation-revenue-trap-f452e242dca4Source snippet
The 55393-Query Audit Exposes Google's Citation...The arXiv paper decomposed AI Overview responses into 98,020 atomic claims and found t...
-
Source: reddit.com
Link: https://www.reddit.com/r/Futurology/comments/1jbvgpb/ai_search_engines_cite_incorrect_sources_at_an/Source snippet
AI search engines cite incorrect sources at an alarming 60...A new study from Columbia Journalism Review's Tow Center for Digital Journa...
-
Source: medium.com
Link: https://medium.com/machine-relations/how-ai-search-decides-which-brands-to-cite-92bedfd85442Source snippet
How AI Search Decides Which Brands to CiteIt also decomposed responses into 98,020 atomic claims and found that 11.0% were unsupported by...
-
Source: ziptie.dev
Link: https://ziptie.dev/blog/myths-about-ai-search-that-are-harmful/
Topic Tree